刚刚,开源大模型的新王诞生了:超越GPT-4o,模型还能自动纠错
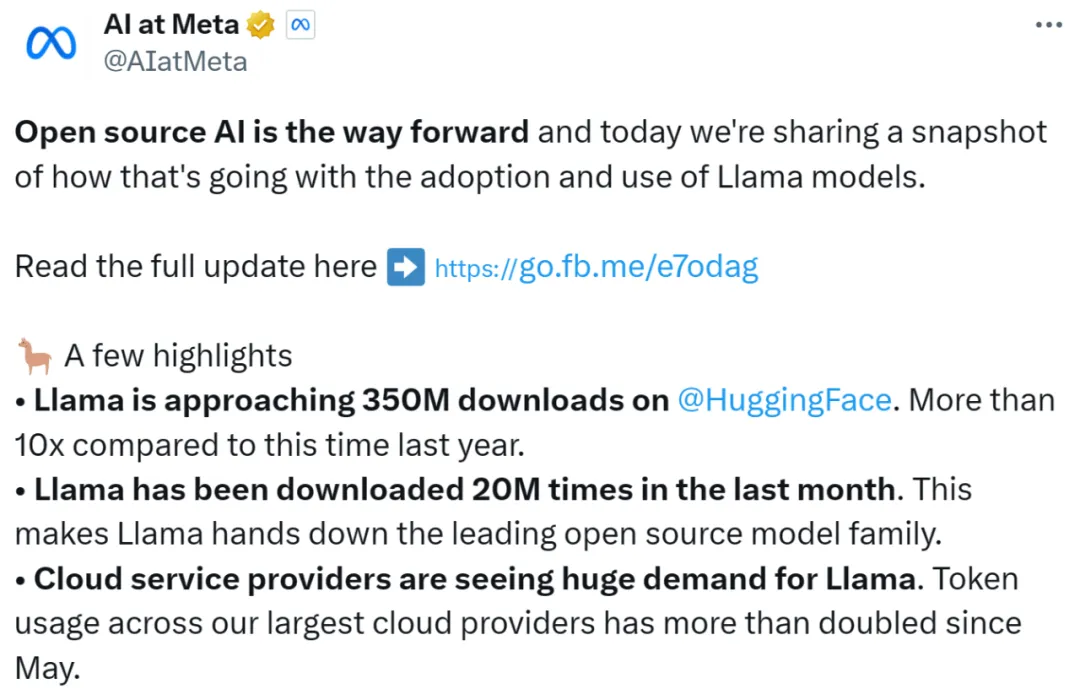
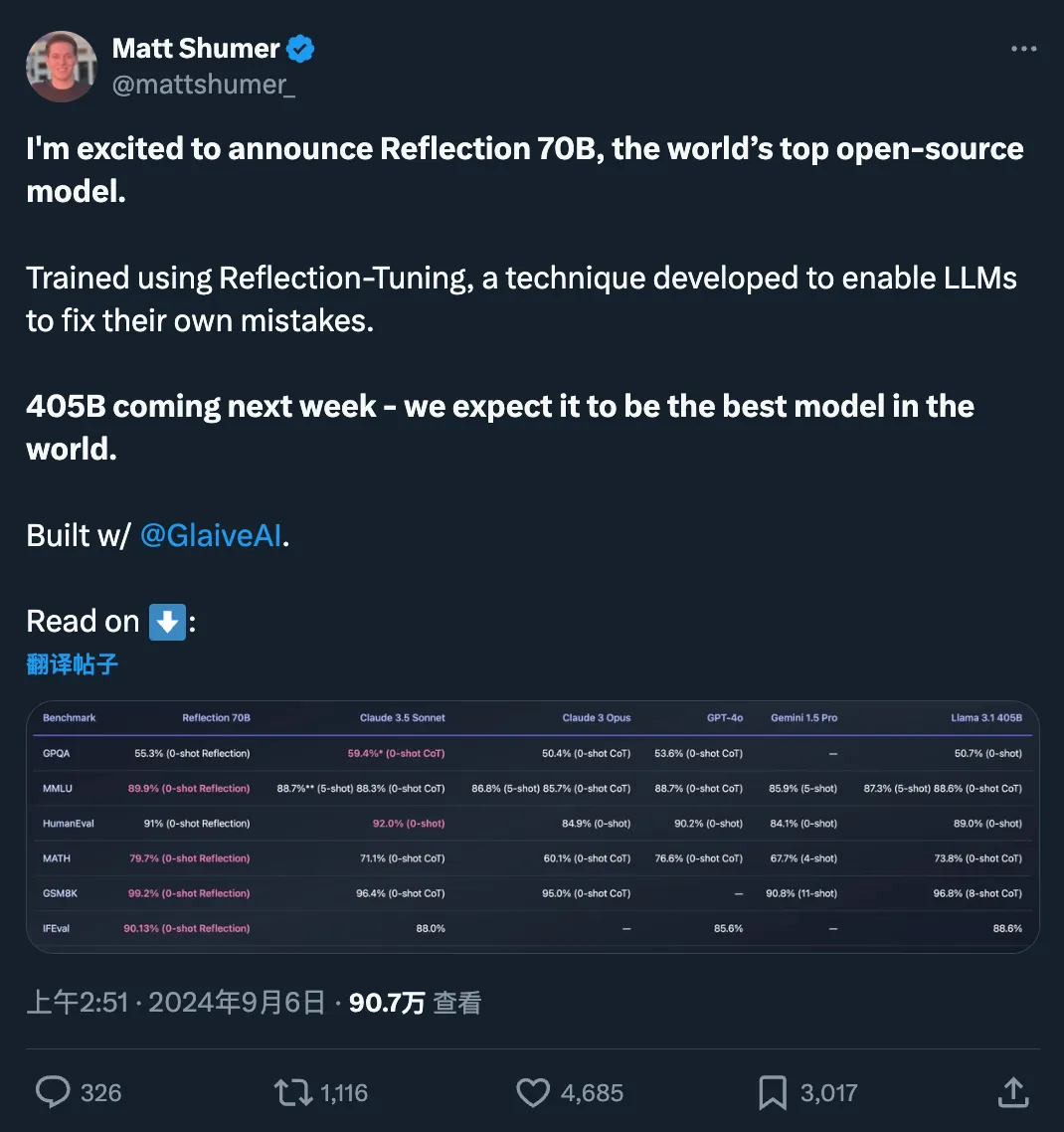
刚刚,开源大模型的新王诞生了:超越GPT-4o,模型还能自动纠错快速更迭的开源大模型领域,又出现了新王:Reflection 70B。 横扫 MMLU、MATH、IFEval、GSM8K,在每项基准测试上都超过了 GPT-4o,还击败了 405B 的 Llama 3.1。 这个新模型 Reflection 70B,来自 AI 写作初创公司 HyperWrite。
来自主题: AI资讯
8853 点击 2024-09-06 16:36